Properties of Least Square Estimators Linearity Unbiased Blue
The Gauss-Markov theorem states that if your linear regression model satisfies the first six classical assumptions, then ordinary least squares (OLS) regression produces unbiased estimates that have the smallest variance of all possible linear estimators.
The proof for this theorem goes way beyond the scope of this blog post. However, the critical point is that when you satisfy the classical assumptions, you can be confident that you are obtaining the best possible coefficient estimates. The Gauss-Markov theorem does not state that these are just the best possible estimates for the OLS procedure, but the best possible estimates for any linear model estimator. Think about that!
In my post about the classical assumptions of OLS linear regression, I explain those assumptions and how to verify them. In this post, I take a closer look at the nature of OLS estimates. What does the Gauss-Markov theorem mean exactly when it states that OLS estimates are the best estimates when the assumptions hold true?
The Gauss-Markov Theorem: OLS is BLUE!
The Gauss-Markov theorem famously states that OLS is BLUE. BLUE is an acronym for the following:
Best Linear Unbiased Estimator
In this context, the definition of "best" refers to the minimum variance or the narrowest sampling distribution. More specifically, when your model satisfies the assumptions, OLS coefficient estimates follow the tightest possible sampling distribution of unbiased estimates compared to other linear estimation methods.
Let's dig deeper into everything that is packed into that sentence!
What Does OLS Estimate?
Regression analysis is like any other inferential methodology. Our goal is to draw a random sample from a population and use it to estimate the properties of that population. In regression analysis, the coefficients in the equation are estimates of the actual population parameters.
The notation for the model of a population is the following:

The betas (β) represent the population parameter for each term in the model. Epsilon (ε) represents the random error that the model doesn't explain. Unfortunately, we'll never know these population values because it is generally impossible to measure the entire population. Instead, we'll obtain estimates of them using our random sample.
The notation for an estimated model from a random sample is the following:
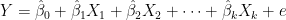
The hats over the betas indicate that these are parameter estimates while e represents the residuals, which are estimates of the random error.
Typically, statisticians consider estimates to be useful when they are unbiased (correct on average) and precise (minimum variance). To apply these concepts to parameter estimates and the Gauss-Markov theorem, we'll need to understand the sampling distribution of the parameter estimates.
Sampling Distributions of the Parameter Estimates
Imagine that we repeat the same study many times. We collect random samples of the same size, from the same population, and fit the same OLS regression model repeatedly. Each random sample produces different estimates for the parameters in the regression equation. After this process, we can graph the distribution of estimates for each parameter. Statisticians refer to this type of distribution as a sampling distribution, which is a type of probability distribution.
Keep in mind that each curve represents the sampling distribution of the estimates for a single parameter. The graphs below tell us which values of parameter estimates are more and less common. They also indicate how far estimates are likely to fall from the correct value.
Of course, when you conduct a real study, you'll perform it once, not know the actual population value, and you definitely won't see the sampling distribution. Instead, your analysis draws one value from the underlying sampling distribution for each parameter. However, using statistical principles, we can understand the properties of the sampling distributions without having to repeat a study many times. Isn't the field of statistics grand?!
Hypothesis tests also use sampling distributions to calculate p-values and create confidence intervals. For more information about this process, read my post: How Hypothesis Tests Work.
Related post: Sampling Distributions
Unbiased Estimates: Sampling Distributions Centered on the True Population Parameter
In the graph below, beta represents the true population value. The curve on the right centers on a value that is too high. This model tends to produce estimates that are too high, which is a positive bias. It is not correct on average. However, the curve on the left centers on the actual value of beta. That model produces parameter estimates that are correct on average. The expected value is the actual value of the population parameter. That's what we want and satisfying the OLS assumptions helps us!

Keep in mind that the curve on the left doesn't indicate that an individual study necessarily produces an estimate that is right on target. Instead, it means that OLS produces the correct estimate on average when the assumptions hold true. Different studies will generate values that are sometimes higher and sometimes lower—as opposed to having a tendency to be too high or too low.
Minimum Variance: Sampling Distributions are Tight Around the Population Parameter
In the graph below, both curves center on beta. However, one curve is wider than the other because the variances are different. Broader curves indicate that there is a higher probability that the estimates will be further away from the correct value. That's not good. We want our estimates to be close to beta.

Both studies are correct on average. However, we want our estimates to follow the narrower curve because they're likely to be closer to the correct value than the wider curve. The Gauss-Markov theorem states that satisfying the OLS assumptions keeps the sampling distribution as tight as possible for unbiased estimates.
The Best in BLUE refers to the sampling distribution with the minimum variance. That's the tightest possible distribution of all unbiased linear estimation methods!
Gauss-Markov Theorem OLS Estimates and Sampling Distributions
As you can see, the best estimates are those that are unbiased and have the minimum variance. When your model satisfies the assumptions, the Gauss-Markov theorem states that the OLS procedure produces unbiased estimates that have the minimum variance. The sampling distributions are centered on the actual population value and are the tightest possible distributions. Finally, these aren't just the best estimates that OLS can produce, but the best estimates that any linear model estimator can produce. Powerful stuff!
Source: https://statisticsbyjim.com/regression/gauss-markov-theorem-ols-blue/
0 Response to "Properties of Least Square Estimators Linearity Unbiased Blue"
Post a Comment